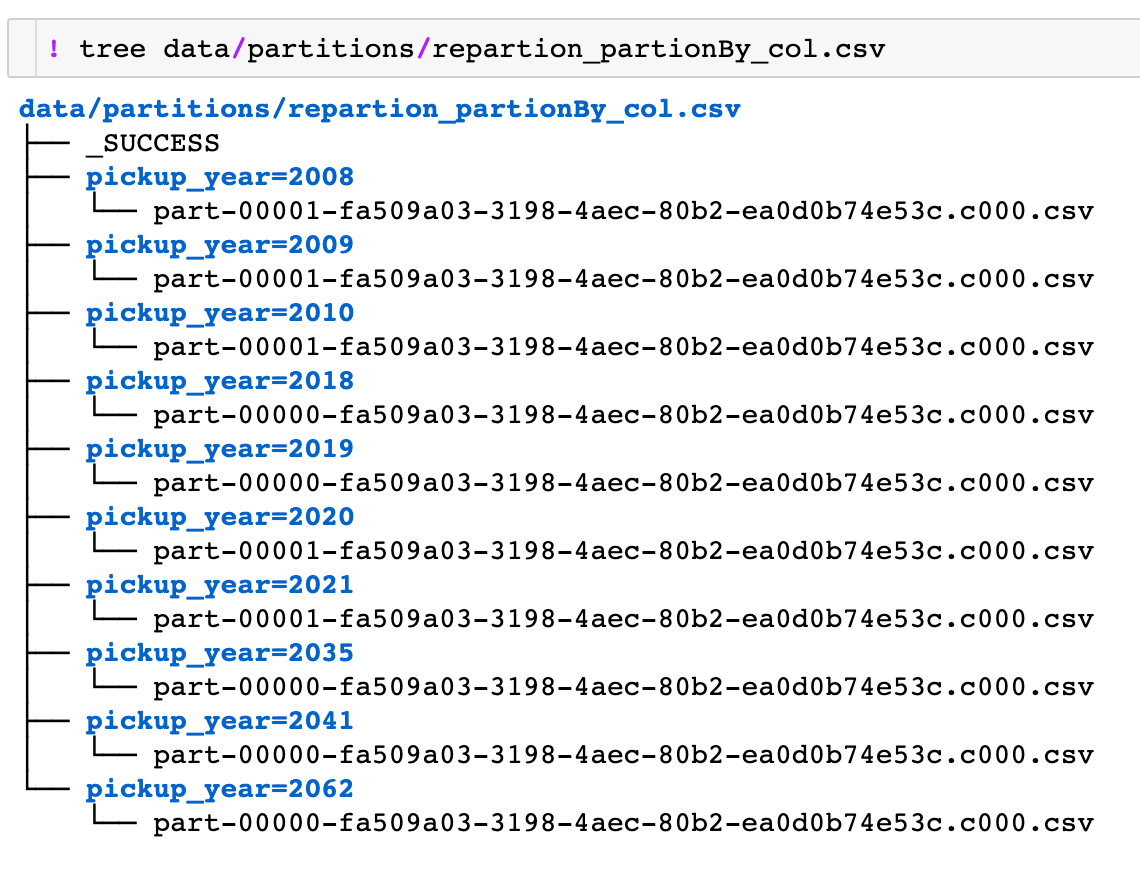
Increase Number Of Partitions In Spark. Spark can pick the proper shuffle partition number at runtime. when decreasing the number of partitions one can use coalesce, which is great because it doesn't cause a shuffle and. how to increase the number of partitions. if i want to have a value in each partition, i usually have to increase the number of partition. Use repartition() to increase the number of partitions, which. you do not need to set a proper shuffle partition number to fit your dataset. But in my example, i still had a partition that stored two values in the. we can adjust the number of partitions by using transformations like repartition() or coalesce(). how does one calculate the 'optimal' number of partitions based on the size of the dataframe? If you want to increase the partitions of your dataframe, all you need to run is the repartition() function. in simple words, repartition () increases or decreases the partitions, whereas coalesce () only decreases the number of partitions efficiently.
from medium.com
we can adjust the number of partitions by using transformations like repartition() or coalesce(). how does one calculate the 'optimal' number of partitions based on the size of the dataframe? Spark can pick the proper shuffle partition number at runtime. in simple words, repartition () increases or decreases the partitions, whereas coalesce () only decreases the number of partitions efficiently. if i want to have a value in each partition, i usually have to increase the number of partition. If you want to increase the partitions of your dataframe, all you need to run is the repartition() function. Use repartition() to increase the number of partitions, which. when decreasing the number of partitions one can use coalesce, which is great because it doesn't cause a shuffle and. But in my example, i still had a partition that stored two values in the. how to increase the number of partitions.
Managing Partitions with Spark. If you ever wonder why everyone moved
Increase Number Of Partitions In Spark how to increase the number of partitions. when decreasing the number of partitions one can use coalesce, which is great because it doesn't cause a shuffle and. Use repartition() to increase the number of partitions, which. Spark can pick the proper shuffle partition number at runtime. how to increase the number of partitions. But in my example, i still had a partition that stored two values in the. if i want to have a value in each partition, i usually have to increase the number of partition. you do not need to set a proper shuffle partition number to fit your dataset. we can adjust the number of partitions by using transformations like repartition() or coalesce(). in simple words, repartition () increases or decreases the partitions, whereas coalesce () only decreases the number of partitions efficiently. If you want to increase the partitions of your dataframe, all you need to run is the repartition() function. how does one calculate the 'optimal' number of partitions based on the size of the dataframe?